La puissance des pointeurs : les arbres |
|
|
|
fichier : arbres.cpp |
Au cours précédent, je vous avait présenté la liste chaînée, qui est une structure de données complexe, réalisée à l'aide de pointeurs. Cette structure nous avait permis de placer des valeurs dans une liste, et de les retirer de là. Parmis les extensions proposées, il y avait la construction d'une liste chaînée double qui nous permettait d'accélerer les temps de suppression d'un élément. Par contre, cette extension ne nous avait pas permis de réduire les temps de recherche d'un élément dans la liste.
Il existe une autre structure complexe appelée arbre. En réalité, c'est comme les listes chaînées : il en existe de toutes les sortes : arbres binaires, arbres rouge-noir, etc... Chaque type d'arbre possède ses propres caractéristiques, et on choisira son végétal informatique en fonction de l'utilisation qu'on souhaite en faire.
Dans ce cours, je me propose de vous montrer une type d'arbre très simple (et donc l'un des moins efficaces), qui est de la famille des arbres binaires. Il va nous permettre de trier des éléments, et donc d'effectuer des recherches qui, vous l'aurez deviné, seront bien plus rapides qu'avec la liste chaînée.
| Terminologie |
|
Ce petit paragraphe est nécessaire afin de bien comprendre ce dont nous allons parler. Rassurez-vous, ce ne sera pas trop long.
Un arbre est composé de noeuds et de feuilles (les feuilles sont des noeuds particuliers, cf. la définition ci-après), et deux noeuds sont reliés entre eux par une branche. On dira que de chaque noeud partent deux branches, et à chaque extrêmité d'une branche, il y a soit un noeud, soit une feuille.
Les noeuds sont donc, en quelque sorte, un embranchement : il y arrive une branche (la branche mère), et il en repart deux branches filles : une sur la droite et une sur la gauche. Un petit schéma rendra les choses plus claires :
Dans cet exemple (notez que mon bout d'arbre est orienté vers le bas), nous avons trois noeuds, dont une feuille. Le noeud rose est le noeud parent des deux noeuds bleus, qui sont ses deux noeuds fils. Le fils de gauche est lui-même le parent de deux autres noeuds (car il y a deux branches qui partent vers le bas). Par contre, le fils de droite n'a pas de fils : il s'agit alors d'une feuille. Notez bien que le noeud rose est également le fils d'un autre noeud.
Voici la règle de construction de l'arbre :
Enfin, on appelle profondeur de l'arbre, le nombre de branches allant de la racine au noeud le plus bas de l'arbre (le noeud le plus loin de la racine, c'est-à-dire le noeud ayant le plus d'ancêtres).
| Principe de notre arbre |
|
Maintenant que nous avons posé les règles de base pour construire un arbre, nous allons y ajouter les notres, qui vont nous permettre de saisir l'intérêt de cette structure.
Si vous vous souvenez bien des listes chaînées, je vous avais proposé une extension qui permettait de garder une liste triée tout le temps. Pour notre arbre, nous allons faire pareil, c'est-à-dire que lors de l'insertion et lors de la suppression d'un élément, nous allons nous débrouiller pour garder l'arbre trié.
Mais comment notre arbre est-il trié ? En réalité, le principe est très simple. Chaque noeud de notre arbre contient une valeur (un int, pour changer). L'arbre sera trié si on resptecte la règle suivante pour chaque noeud parent : le fils de gauche doit contenir une valeur inférieure au parent, et le fils de droite doit contenir une valeur supérieure au parent. Voici un exemple d'arbre trié de cette façon :
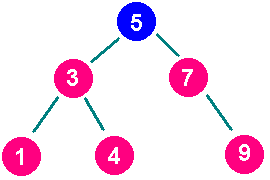
Vous constaterez un phénomène important : tous les noeuds contenant une valeur inférieure à la racine (en bleu) sont dans la partie gauche de l'arbre, et tous les noeuds comportant une valeur supérieure à la racine sont dans la partie gauche. Cela est vrai non seulement pour la racine, mais aussi pour tous les noeuds de l'arbre. Une conséquence de cet ordonnancement est que le noeud contenant la plus petite valeur est le noeud situé le plus à gauche dans l'arbre (alors que le noeud contenant la valeur la plus grande se trouve à droite). Au passage, notons que la profondeur de cet arbre est de 2 (il y a deux branches à traverser pour aller de la racine au noeud le plus éloigné - 1, 4 ou 9 dans ce cas).
Chaque nouvel élément inséré deviendra une feuille : il sera donc inséré à une position vide. Pour connaître sa position, on se place d'abord à la racine. On compare alors la valeur de la racine à la valeur du noeud à insérer, et on va à gauche si notre nouveau noeud est plus petit que la racine, à droite dans le cas contraire, puis on recommence la comparaison avec le noeud sur lequel on vient de tomber. Puis on continue ainsi jusqu'à ce qu'on arrive à une place libre. A ce moment, on peut placer notre nouveau noeud.
Pour en retirer un élément, c'est un petit peu plus subtil : on remplace cet élément par l'un de ses fils, et on replace l'autre fils dans l'arbre, afin qu'il soit de nouveau à la bonne position (et de manière naturelle, tous ses fils suivront pour se placer eux-aussi à la bonne place). Voici un exemple explicatif :

Supprimons maintenant l'élément "4". Il nous faut alors mettre l'élément "8" à sa place, et replacer l'élément 2 dans l'arbre (en repartant du haut) pour qu'il arrive à la bonne place. Après la manipulation, on obtient :

On a donc bien remonté l'élément "8" (et tous ses fils qui ont suivi docilement), puis on a replacé l'élément "2" (là encore, les fils ont suivi). On constate bien sûr que l'arbre est de nouveau trié. Au passage, sa profondeur est maintenant 5, alors qu'elle était de 4 auparavant.
Comparons rapidement cette nouvelle structure aux listes chaînées. Notre arbre, tel qu'il est dans l'exemple ci-dessus, contient 13 noeuds, et sa profondeur est 5. Une liste chaînée contenant ces mêmes éléments aurait eu une longueur de 13, ce qui veut dire qu'au pire des cas, pour une recherche, on aurait regardé les valeurs de 13 éléments. Ici, la recherche est bien plus efficace, puisqu'au maximum, on regardera 5 noeuds, soit la profondeur de l'arbre.
Encore une fois, ce modèle d'arbre n'est pas le plus efficace, et il n'est pas impossible que tous les noeuds soient alignés, de manière à ce que la profondeur de l'arbre soit égale au nombre d'éléments présents, ce qui nous ramènerait à la performance d'une liste chaînée. Mais deux arguments jouent en faveur des arbres : d'une part, la plupart du temps, l'arbre a une profondeur inférieure au nombre d'éléments (à moins d'avoir mal choisi ses données), d'autre part, il existe des modèles bien plus performants. Ainsi, l'un de ces modèles assure que chaque "étage" de l'arbre soit plein avant d'en entammer un autre. Ce dernier modèle est appelé arbre parfait, ou Heap (qui n'a rien à voir avec la mémoire du même nom), et je vous invite à étudier cette structure par vous-même, si vous êtes un fan de performances.
| Réalisation |
|
Une fois toutes les explications théoriques dispensées, nous pouvons passer à la pratique. Bien entendu, comme pour la liste chaînée, une struct va représenter un noeud :
| struct Noeud { int valeur; Noeud* fils_droite; Noeud* fils_gauche; }; Noeud* arbre = NULL; |
Nous retrouvons le principe de la liste chaînée, à savoir que chaque noeud connait ses deux successeurs et contient une valeur.
Passons maintenant aux fonctions qui vont nous permettre d'utiliser notre arbre (encore une fois déclaré global). Cette fois-ci, les fonctions seront au nombre de 4 :
|
void Placer(Noeud* noeud) void Ajouter(int valeur) |
Contrairement à la dernière fois, ce n'est pas la fonction Ajouter() qui va placer le nouvel élément dans la liste. A cet effet, on a ajouté la fonction Placer(). En effet, il était intéressant d'en faire une fonction à part, étant donné qu'on en a également besoin dans Supprimer() pour replacer le fils de gauche dans l'arbre. Sinon, les autres fonctions sont similaires à celles du cours dernier. Passons maintenant à l'affichage puis au main() :
|
void Afficher(Noeud* racine) |
La fonction Afficher() est différente de la dernière fois : elle fonctionne de manière récursive (si vous ne connaissez pas la récursivité, cette page est consacrée à ce sujet). En effet, elle commence par s'appeler pour le fils de gauche (s'il existe), puis elle affiche la racine qu'on lui a donné, puis elle s'appelle pour le fils de droite (s'il existe). Cela permet, en trois lignes, d'afficher la totalité de l'arbre. Bien sûr, l'affichage se fait dans l'ordre croissant :
|
1
2 4 9 10 14 15 16 1 2 9 10 14 15 16 |
L'élément 4 a bien été supprimé, c'est heureux.
Voilà un cours bien fourni. Vous savez maintenant à quoi ressemble un arbre en informatique, et vous pouvez par vous-même vous lancer dans la programmation d'arbres plus complexes, mais souvent plus efficaces (et donc plus intéressants à programmer, mais si!). Mais avant cela, nous allons nous assurer que vous ayez bien tout compris :
|
| Conclusion |
|
Voilà. Nous avons, au long des deux cours précédents, étudié deux types de structures complexes très utilisées en programmation, dont l'incontournable liste chaînée. Non seulement cela nous a permis de nous familiariser avec les pointeurs, mais nous a également fourni des outils algorithmiques indispensables.
On m'a récemment fait une remarque légitime : les programmes proposés pour l'instant ne sont pas d'un amusant flagrant. Rassurez-vous : dans le prochain cours, nous verrons la manipulation de chaînes de caractères. Celles-ci sont essentielles, car elles permettent de fournir des informations à l'utilisateur, et elles représentent une part importante des données qu'un programme peut avoir à traiter. Nous verrons deux manières de manipuler ces chaines de caractères : la manière du C, encore largement répendue, même dans les programmes C++, puis la manière C++, avec, à la clé, une petite introduction aux classes.
D'ici là, je vous souhaite beaucoup de plaisir à programmer.
| Voir aussi |
|